之前介绍EndNote的时候讲到它可以快速检索一个领域的文献,并且提供全文下载,以及很方便的向word插入参考文献。但是EndNote查找出来的文献还是具有一定的局限性,查找出来的文章非常多,需要一个个去看摘要做筛选,而且作为一个新手来说,你没办法准确的找到该领域最应该读的核心文献。
HistCite的产生很好的解决了上述问题,HistCite 这款软件是 Thomson Reuters (汤森路透)公司开发的,和 WOS 是一家公司,所以 HistCite 只支持 WOS 数据库,对于 Scopus 等数据库则无能为力,不过 Github 上面有人写了一个可以将 Scopus 导入 Histcite 进行分析的脚本——Scopus2Histcite。这个脚本的主要作用就是将Scopus导出的txt文件格式转化成WOS的txt文件格式,(Scopus导出的txt文件和WOS导出的文件其实内容上都差不多,但是就是字段之间不一样,因此,就需要把字段进行替换。比如在Scopus导出的txt文件中作者的字段叫auth,而WOS的作者字段叫author,那么只支持WOS的HistCite肯定就识别不出auth字段呀 ),直接将转换后的Scopus库txt文件放入HistCite Pro 2.1中就可以运行成功。
2016年10月,汤森路透知识产权与科技业务被 Clarivate Analytics (科睿唯安)公司收购了,从此 WOS 也是归该公司所有,因此导出的数据纯文本也发生了些许变化,从而不能直接导入 HistCite 进行分析。就有人在这个基础上做出了改进开发出HistCite Pro。HistCite Pro 完全兼容新的文件格式!
HistCite Pro 2.1安装
下载链接:HistCite Pro 2.1
下载好之后解压,HistCite Pro 2.1的目录如下图:

其中,TXT是用于存放从WOS中导出的文献数据集txt文本,main.exe是HistCite Pro的入口程序,双击运行之后根据控制台信息,选择1就可以调出浏览器显示HistCite Pro的主界面,这个界面是显示在127.0.0.1:1925端口,可以在HistCite Pro运行后在浏览器中输入地址直接访问。
HistCite Pro 2.1使用
1、从WOS导出数据
进入Web of Science官网。选择Web of Science核心合集(因为不是核心合集点击导出是没有全记录与引用的参考文献这个内容选项的,就会导致HistCite不能从引用的参考文献中发现核心文献),输入基本检索信息,按照被引频次排序,点击导出为其他文件格式,记录内容选择全记录与引用的参考文献,文件格式为纯文本。
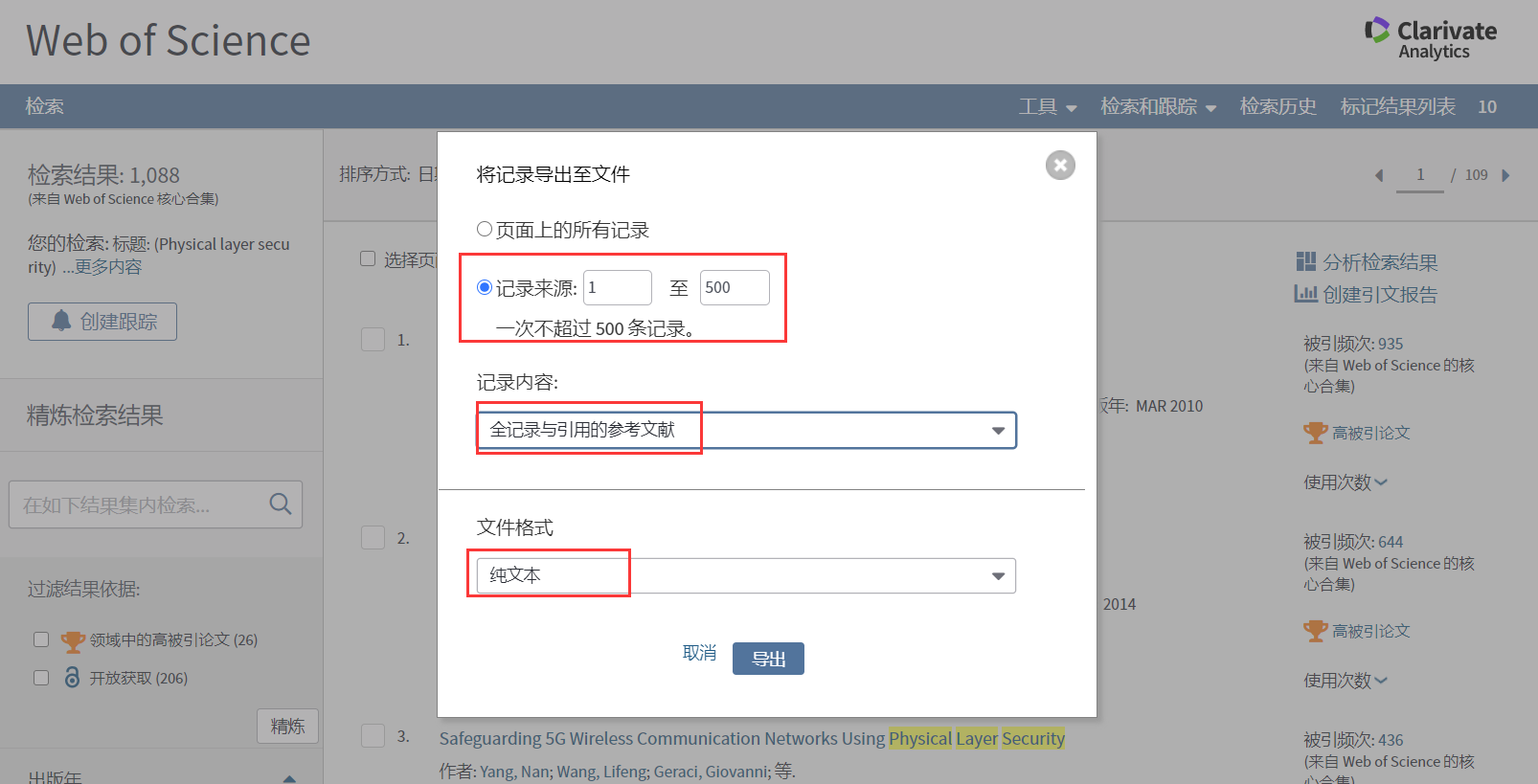
注意:在弹出的菜单中,记录数填写1到500,因为每次最多只能导出500篇文献,所以上面的2819篇文献需要分成6次导出,后面导出的时候依次填写501到1000、1001到1500等等。
2、在HistCite Pro 2.1中显示数据文本
将导出的txt文本都放入HistCite Pro 2.1目录下的TXT文件夹(如果需要分析完一个方向之后还需要分析另一个方向的数据文本,需要将原来放在TXT文件夹下的数据文本拿走,然后放入新的数据文本。总之,就是TXT目录下只能放置一个数据文本(像前面的多于500条记录需要分文件夹的,导出填写写501到1000、1001到1500之后,虽然文件有三个,但是也算一个数据文本))。TXT文件夹下放置需要分析的数据文本,然后双击main.exe。在跳出的控制窗口输入1即可在弹出的浏览器中查看分析结果,还可以在别的浏览器输入127.0.0.1:1925访问页面。
3、HistCite Pro 2.1四个重要参数
打开浏览器访问页面如下:
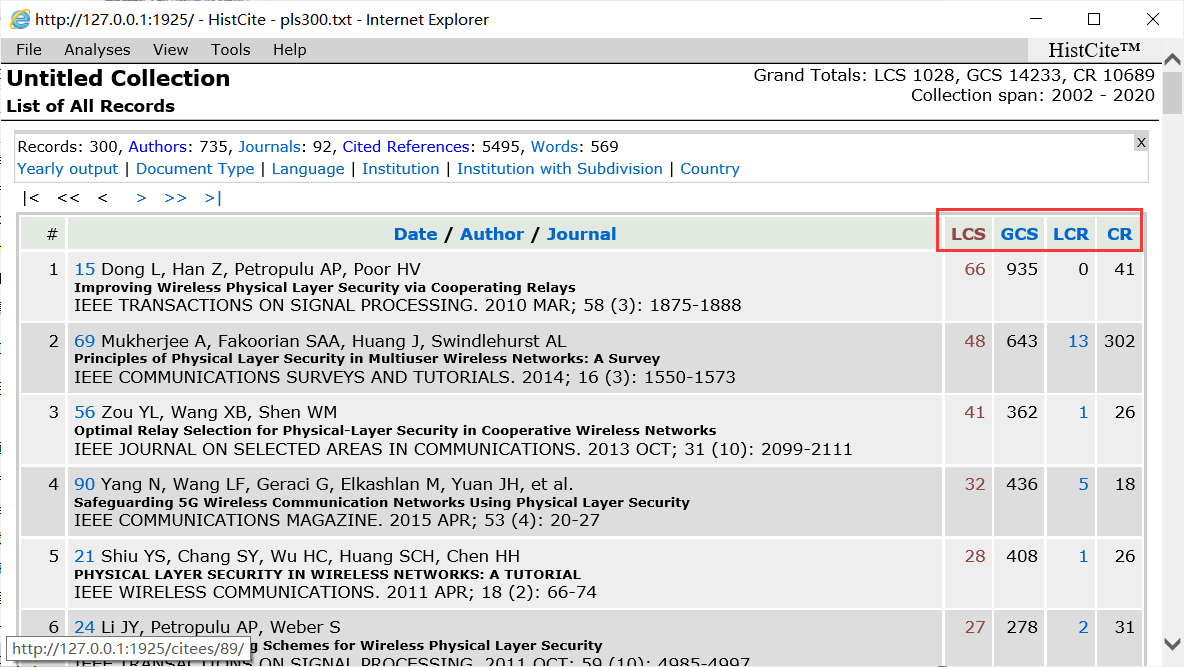
在HistCite Pro 2.1中只要是蓝色的字段都是可以点击的。可以看到HistCite Pro 2.1把WOS文本数据表格化显示出来,我们可以依据七个信息(日期,作者,期刊,LCS,GCS,LCR,CR)进行排序显示。其中,每篇文章都有LCS,GCS,LCR,CR这四个参数,它们分别表示:LCS是本地数据库文章中引用该文章的文章个数,GCS是该文章总的被引用次数,LCR该文章引用了多少本地数据库文章,CR该文章总共引用了多少文章。其实就是L表示本地,那本地又是啥意思呢,就是指我们从WOS找到的1500条数据,每个数据是一篇文章,加了L的就是在本地数据范围内找,LCS就是这篇文章被本地数据库的其他文章引用了多少次,LCR就是这篇文章引用了多少本地数据库文章。不难看出,最有价值的就是LCS,有些文章GCS很高,但是并不是咱们研究范围内的这些文章引用,就有很多不相关性,所以一般都是按照LCS排序,选择LCS参数比较高的文章。
一般的LCS很高,但是LCR很低,甚至为0的文章,说明这篇文章是开创性的文章,后续的文章都是受他启发而来。而LCR很高的文章说明这是一篇总结性的文章,对前人的多方面工作做了概述,也可以看一眼。
4、HistCite Pro 2.1画图
找到上方工具栏Tools选择graph maker:
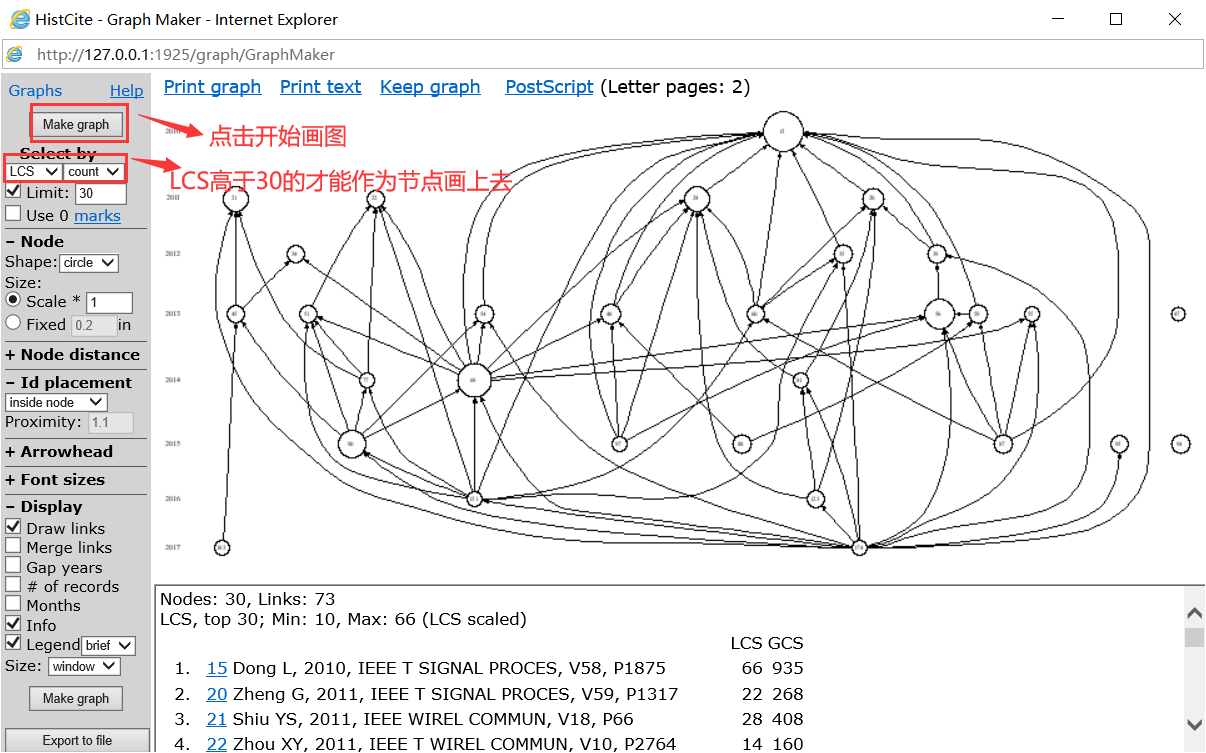
上方的节点越大,越多箭头指向它表示被引用的越多,最下方的就是LCR很高的文章,可以看到它指向了很多节点。根据节点上的序号可以看出是哪一篇文章,也可以把鼠标放在相应节点上,也会显示文章信息。
5、查找遗漏文献
因为是按照关键词进行查找,而有的核心文章可能标题中没有关键词信息,就不会在我们搜集的本地数据库中。那找到它们也很简单,点击Cited References,就会显示出本地数据库文章中引用的文章,按照被本地数据库文章引用的次数降序排序。蓝色字体的表示在本地数据库中,黑色字体的表示不在。点击黑色列表项的WOS,就可以在WOS中进行查找。
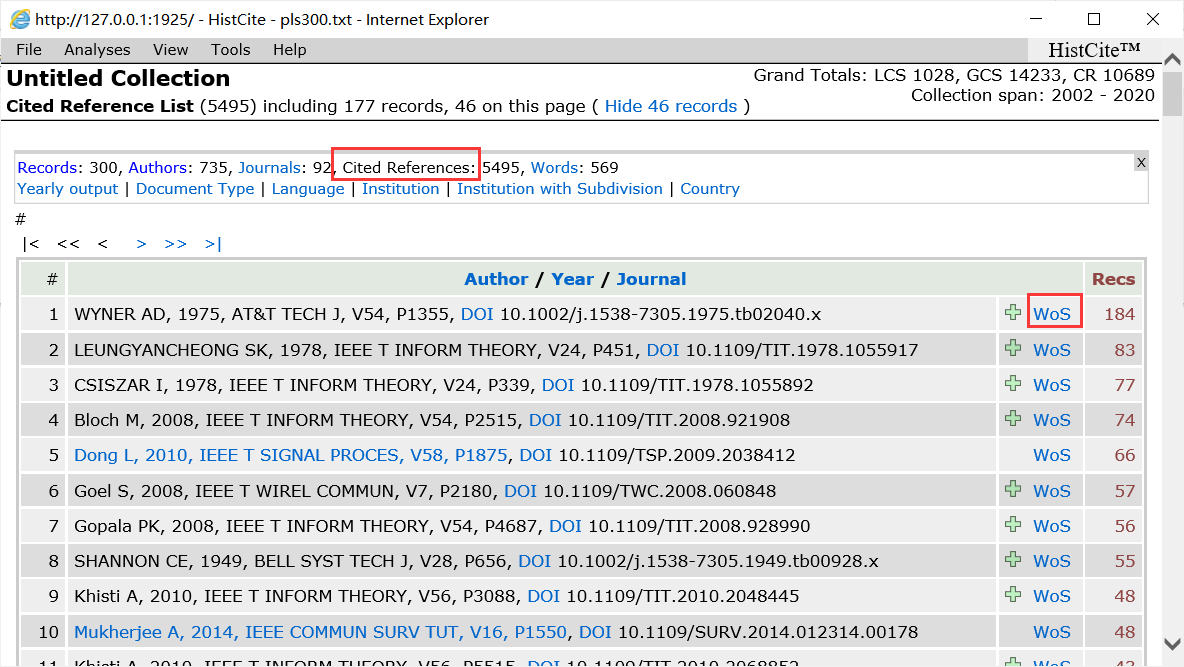
但是这里会有一个bug,因为Histcite对WOS地址解析出现错误。
首先,复制网址。在浏览器中打开 Web of Science 网页,点击【被引参考文献检索】标签(英文版是【Cited Reference Search】)。复制当前页面的网址,后面要用。网址格式为:http://apps.webofknowledge.com/UA_CitedReferenceSearch_input.do?SID=**&product=UA&search_mode=CitedReferenceSearch,注意最后以 CitedReferenceSearch 结尾。
然后,然后在 Histcite 工具栏 tools下拉菜单中选择 Settings 点击。
在弹出的对话框中,往下找到 WoS link 这一栏,默认选择是 Universal setup,改选 Manual setup version 4,然后在 ISI web of knowledge 4 location URL 下面的框里粘贴刚才复制的网址,再点击【Set】即可。
然后继续进行点击WOS操作就可以在弹出的浏览器中找到我们需要的文章啦。
6、文献记录导出到Endnote
首先点击菜单栏中Tools下的Mark&Tag选项,调出标记选择工具栏。
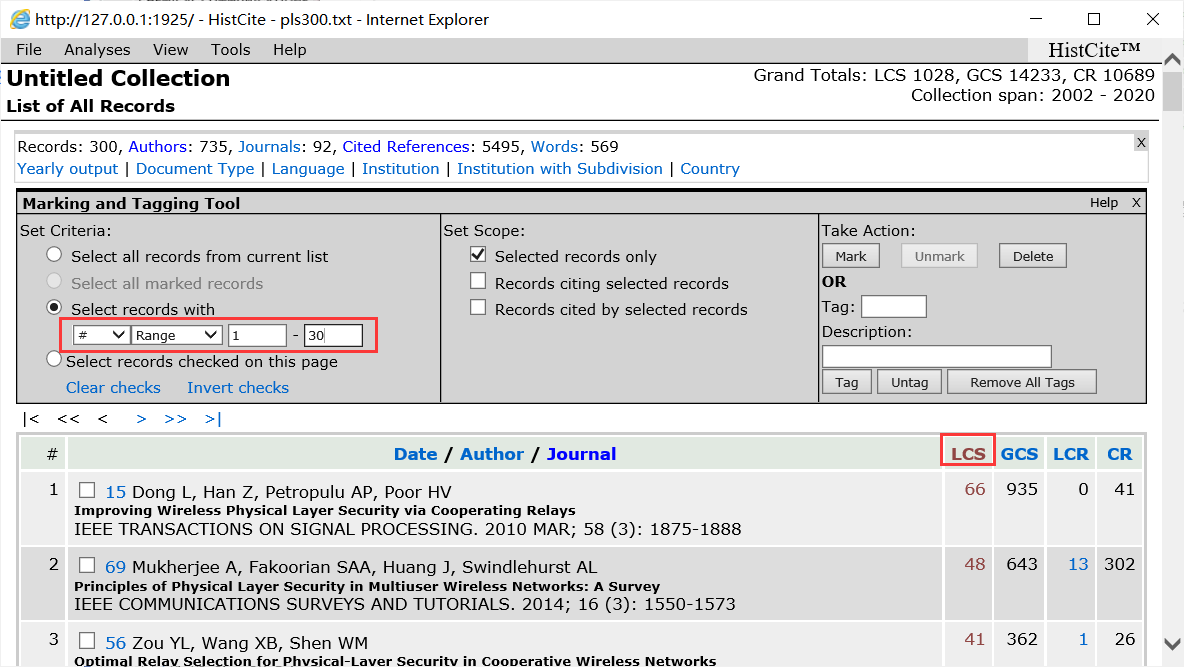
按照LCS排序,然后在红框的range中填写范围,然后再点击第三栏take action的mark(我忘记框出来了)
然后就会发现多了一个Mark项,点击它就可以得到30个文献记录。
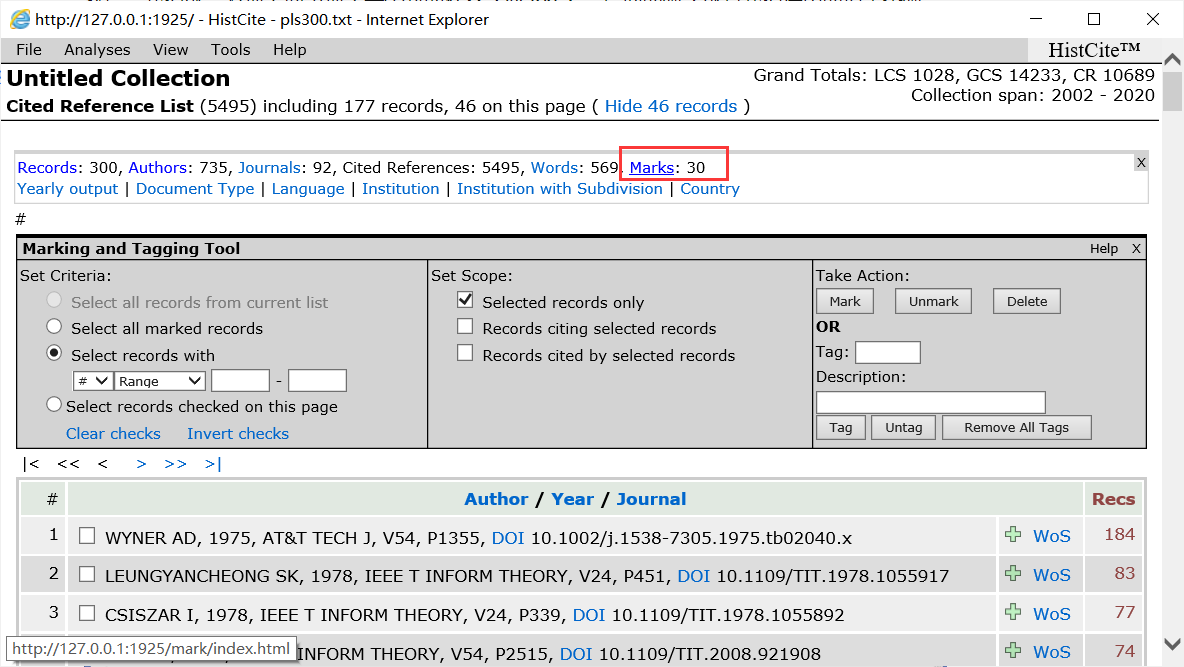
然后在找到export,导出就行,点击了Records之后会在底部弹出是否保存,点击保存就行。
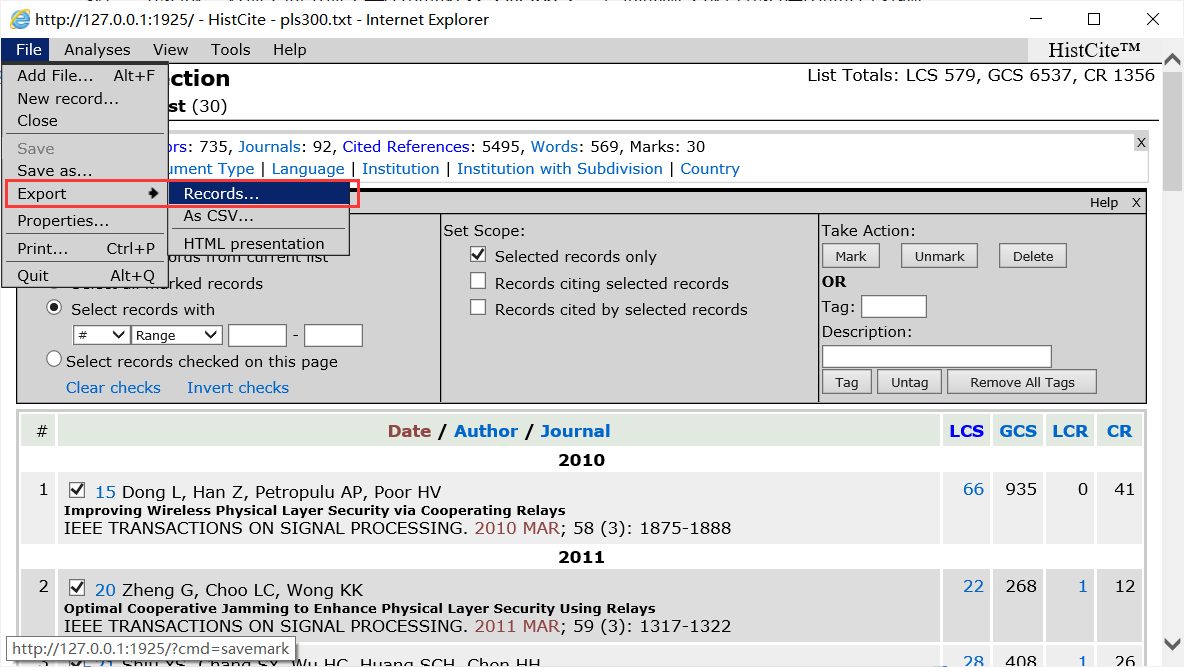
成功导出后得到一个 .hci 格式的文本文件,直接修改后缀为 txt。
打开Endnote,依次点击File、Import、File…按钮。然后选择刚才的txt文件,在弹出来的弹框中Import Option 选择 Multi-Filter (Special)**,Duplicates 选择 **Import All,Text translation 选择UTF-8,然后点击Import按钮即可导入。
好啦,今天的总结完毕,github上的小绿格又多了一个,从今天开始就看我找的文献啦。